


Введение
Файловая система «ReFS» является дальнейшим развитием «NTFS». поддерживает точки повторной обработки (reparse points) – технологию, которая ранее содержалась только в файловой системе «NTFS». Через точки повторной обработки реализована поддержка символьных ссылок и точек монтирования в Windows.
Основные функции:
- Целостность метаданных с контрольными суммами.
- Integrity streams: метод записи данных на диск для дополнительной защиты данных при повреждении части диска.
- Транзакционная модель «allocate on write» (copy on write).
- Большие лимиты на размер разделов, файлов и директорий.
- Организация пулов и виртуализация для более простого создания разделов и управления файловой системой.
- Сегментация последовательных данных «data sriping» для повышения производительности, избыточная запись для отказоустойчивости.
- Поддержка техники чистки диска в фоновом режиме «disk scrubbing» для выявления скрытых ошибок.
- Спасение данных вокруг повреждённого участка на диске.
- Общие пулы хранения данных между машинами для дополнительной отказоустойчивости и балансировки нагрузки.
- Совместима с набором широко используемых функций «NTFS».
- Верификация и автоисправление данных.
- Максимальная масштабируемость.
- Невозможность полного отключения файловой системы за счёт изоляции сбойных участков.
- Гибкая архитектура с использованием функции «Storage Spaces», которая задумана и реализована специально для «ReFS».
В дополнение, «ReFS» унаследует многие функции и семантики «NTFS», включая шифрование «BitLocker», списки контроля доступа «ACL», журнал «USN», уведомления об изменениях, символьные ссылки, точки соединения «junction points», точки монтирования «mount points», точки повторной обработки «reparse points», снимки тома, «ID» файлов и «oplock».
Конечно же, данные с «ReFS» будут доступны для клиентов через те же «API», которые используются сегодня во всех операционных системах для доступа к разделам «NTFS».
Особенности
Особенности файловой системы «ReFS»:
Файловая система использует контрольные суммы для метаданных, а также может использовать контрольные суммы для данных файла. Во время чтения или записи файла, система проверяет контрольную сумму что бы убедиться в её правильности. Таким образом осуществляется обнаружение искаженных данных в режиме реального времени.
При обнаружении поврежденных данных, которые не имеют альтернативной копии для восстановления, такие данные сразу же будут удалены с диска. Перезагрузка или отключение устройства в таком случае не потребуется, как в случае с «NTFS».
Необходимость использования утилиты chkdsk полностью исчезает, потому как файловая система автоматически корректируется сразу в момент возникновения ошибки. Новая система устойчива и к другим вариантам повреждения данных.
Более высокая надежность хранения данных. Для метаданных и содержимого файлов «ReFS» использует B+-деревья. Размеры файлов, томов, количество файлов в каталоге ограничены 64-битным числом. А свободное место на диске описывается 3 отдельными иерархическими таблицами для малых, средних и больших фрагментов свободного пространства. Имена файлов и длина пути ограничена 32 кибибайтами, для хранения которых используется «Unicode».
Новая файловая система также устойчива к повреждению данных другими способами. Например, когда вы обновляете метаданные файла – например, название файла – файловая система «NTFS» будет напрямую изменять метаданные файла. Если ваш компьютер выйдет из строя или отключится питание во время этого процесса, может произойти повреждение данных. Когда вы обновляете метаданные файла, файловая система ReFS создаст новую копию метаданных. И присвоит файлу обновленные метаданные только после того как будут записаны полностью все новые. Нет опасности, что метаданные файла будут повреждены. Это называется копирование на запись «Copy-on-write».
«ReFS» интегрируется с технологией виртуализации носителей данных «Storage Spaces», которая позволяет применять зеркалирование и объединять несколько физических носителей одного ПК или нескольких по сети.
Система не поддерживает именованные потоки файлов, короткие имена, сжатие и шифрование на уровне файлов «Encrypting File System», а также транзакции «NTFS», жёсткие ссылки, «extended attributes», и дисковые квоты.
Отличия от NTFS
«ReFS» более современна, чем «NTFS», и поддерживает гораздо большие объемы и более длинные имена файлов. В долгосрочной перспективе – это важные улучшения.
В файловой системе «NTFS» путь к файлу ограничен 255 символами. С «ReFS» имя файла может содержать более 30 тис. символов (32768).
«NTFS» имеет теоретический максимальный объем в 16 эксабайт, а у «ReFS» теоретический максимальный объем – более двухсот тысяч (262144) экзабайт. Сейчас это большого значения не имеет и рассчитано на будущее.
В «ReFS» отсутствуют некоторые функции доступные в «NTFS», включая сжатие и шифрование файловой системы, жесткие ссылки, расширенные атрибуты, дедупликацию данных и дисковые квоты. Тем не менее, «ReFS» совместима с различными функциями. Например, если вы не можете выполнять шифрование определенных данных на уровне файловой системы, «ReFS» будет совместима с полным типом шифрования «BitLocker».
Windows 10 не позволит вам форматировать любой старый раздел как «ReFS». В настоящее время можно использовать «ReFS» только для пространства хранения, где её функции помогают защитить данные от повреждений. В Windows Server 2016 можно форматировать тома с помощью «ReFS» вместо «NTFS». Использовать «ReFS» для загрузочного тома нельзя потому как Windows может загружаться только с диска «NTFS».
На данный момент этот тип файловой системы используется только на серверных версиях Windows и в версии Windows Enterprise (LTSC).
Архитектура файловой системы
Несмотря на частые упоминания о схожести «ReFS» и «NTFS» на высоком уровне, речь идет всего лишь о совместимости некоторых структур метаданных. Дисковая реализация структуры ReFS кардинально отличается от других файловых систем Microsoft.
Основными структурными элементами этой файловой системы являются B+ деревья. Все элементы структуры файловой системы могут быть одноуровневыми (листья) или многоуровневыми (деревья). Такой подход позволяет масштабировать практически любой элемент файловой системы. Наряду с реальной 64-битной адресацией всех элементов системы это исключает появление «узких мест» при ее дальнейшем масштабировании.

В дополнение к корневой записи B+дерева все другие записи имеют размер блока метаданных – 16 КБ. Промежуточные (адресные) узлы имеют небольшой размер около 60 байт. Поэтому обычно для описания даже очень больших структур требуется небольшое количество уровней дерева. Такой подход увеличивает общую производительность системы.
Основным структурным элементом файловой системы является «Каталог», представленный в виде B+ дерева с ключом в виде номера объекта папки. В отличие от других подобных файловых систем, файл в «ReFS» не является отдельным ключевым элементом «Каталога», а существует только как запись. Возможно, из-за этой архитектурной особенности «ReFS» не поддерживает «жесткие ссылки».
«Листовые» каталоги – это типизированные записи. Существует три основных типа записей для объекта папки: дескриптор каталога, индексная запись и дескриптор вложенного объекта. Все такие записи упаковываются в отдельное дерево с идентификатором папки. Эго корень является «листом» этого дерева. Это позволяет записывать практически любое количество записей. На нижнем уровне в листьях находится запись дескриптора каталога, содержащая основную информацию о каталоге, такую как имя, стандартную информацию, атрибут имени файла и т. д.
Далее в каталоге находятся так называемые записи указателя: короткие структуры с данными элементов каталога. По сравнению с NTFS эти записи значительно короче, что в меньшей степени перегружает том метаданными. Последними идут записи элементов каталога. Для папок эти элементы содержат имя папки, а также идентификатор папки в «Каталоге» и структуру «стандартной информации». Для файла идентификатор отсутствует, но вместо него в структуре содержатся все основные данные о файле, включая фрагменты файла корня –дерева. Поэтому файл может состоять практически из любого количества фрагментов.
Файлы на диске располагаются блоками по 64 КБ. Адресуются точно так же, как блоки метаданных в кластерах по 16 КБ. «Резидентность» файловых данных в «ReFS» не поддерживается, поэтому файл размером 1 байт на диске займет весь блок размером 64 КБ, что приводит к значительной избыточности хранения для небольших файлов. С другой стороны, это упрощает управление свободным пространством, и процесс распределения под новые файлы выполняется намного быстрее.
Размер метаданных пустой файловой системы составляет около 0,1% от размера самой файловой системы (т. Е. Около 2 ГБ на томе 2 ТБ). Некоторые базовые метаданные дублируются что повышает устойчивость от сбоев.
Структура файловой системы ReFS
Файловую систему «ReFS» можно определить по следующей сигнатуре в самом начале раздела:
00 00 00 52 65 46 53 00 00 00 00 00 00 00 00 00 ...ReFS.........
46 53 52 53 XX XX XX XX XX XX XX XX XX XX XX XX FSRS
Страницы ReFS имеют длину 0x4000 байт.
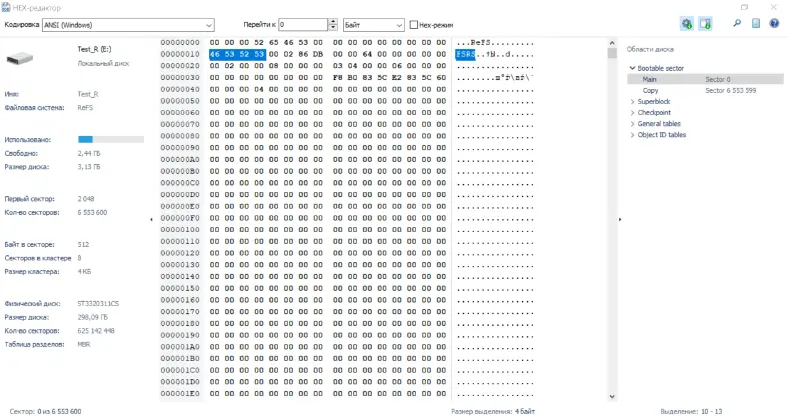
Во всех проверенных системах номер первой страницы равен 0x1e (0x78000 байт после загрузочного раздела, содержащего файловую систему). Это встроенная документация Microsoft, в которой указано, что первый каталог метаданных находится по фиксированному смещению на диске.
Другие страницы содержат различные структуры и таблицы системы, каталогов и томов, а также «журналируемые» версии каждой страницы.
Первый байт каждой страницы – это ее номер.
Первые 0x30 байтов каждой страницы метаданных это Заголовок страницы, который имеют следующий вид:
byte 0: XX XX 00 00 00 00 00 00 YY 00 00 00 00 00 00 00
byte 16: 00 00 00 00 00 00 00 00 ZZ ZZ 00 00 00 00 00 00
byte 32: 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
dword 0 (XX XX) – номер страницы, который является последовательным и соответствует смещению страницы 0x4000;
dword 2 (YY) – номер журнала или порядковый номер;
dword 6 (ZZ ZZ) – это «виртуальный номер страницы», который не является последовательным
Таблица объекта «Object Table», виртуальный номер страницы 0x02 – связывает идентификаторы объектов со страницами, на которых они расположены. Здесь мы видим «AttributeList», состоящий из записей «Key / Value pairs».
По которым можно найти «ID» объекта корневого каталога и получить страницу, на которой он находится:
50 00 00 00 10 00 10 00 00 00 20 00 30 00 00 00 – общая длинна / границы ключей и значений
00 00 00 00 00 00 00 00 00 06 00 00 00 00 00 00 – идентификатор объекта
F4 0A 00 00 00 00 00 00 00 00 02 08 08 00 00 00 – идентификатор страницы / флаги
CE 0F 85 14 83 01 DC 39 00 00 00 00 00 00 00 00 – контрольная сумма
08 00 00 00 08 00 00 00 04 00 00 00 00 00 00 00
Запись таблицы объектов для корневого каталога, содержащая его страницу (0xAF4)
При получении страниц по ID или виртуальному номеру, ищите те, у которых наивысший порядковый номер, поскольку это последние копии механизма «shadow-write».
Каталоги, начиная с корневого и далее, следуют последовательной схеме. Они состоят из последовательных списков структур данных, длина которых определяется значением первого атрибута (атрибуты и списки атрибутов).
Список зачастую имеет префикс атрибута заголовка, определяющего общую длину следующих атрибутов, которые составляют этот список.
В любом случае атрибуты могут быть проанализированы путем повторного анализа по байтам после заголовка страницы каталога, считывания и обработки первого значения для определения следующего количества байтов.
Различные атрибуты принимают различную семантику, включая ссылки на подкаталоги и файлы, а также переходы на дополнительные страницы, содержащие большее количество содержимого каталога.
Структуры в списке каталогов имеют один из следующих форматов:
Базовый атрибут (Base Attribute)
Самый простой базовый атрибут, состоит из блока, длина которого указана в самом начале.
Ниже приведен пример типичного атрибута:
a8 00 00 00 28 00 01 00 00 00 00 00 10 01 00 00
10 01 00 00 02 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 a9 d3 a4 c3 27 dd d2 01
5f a0 58 f3 27 dd d2 01 5f a0 58 f3 27 dd d2 01
a9 d3 a4 c3 27 dd d2 01 20 00 00 00 00 00 00 00
00 06 00 00 00 00 00 00 03 00 00 00 00 00 00 00
5c 9a 07 ac 01 00 00 00 19 00 00 00 00 00 00 00
00 00 01 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 01 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00
Здесь раздел длиной 0xA8, содержит четыре метки времени файла. Подробнее это можно увидеть ниже:
a9 d3 a4 c3 27 dd d2 01 - 2017-06-04 07:43:20
5f a0 58 f3 27 dd d2 01 - 2017-06-04 07:44:40
5f a0 58 f3 27 dd d2 01 - 2017-06-04 07:44:40
a9 d3 a4 c3 27 dd d2 01 - 2017-06-04 07:43:20
Можно с уверенностью предположить, что:
- одно из первых полей любого заданного атрибута содержит идентификатор, подробно описывающий, какой атрибут должен быть проанализирован, или
- контекст задается позицией атрибута в списке.
- атрибуты, соответствующие данному значению, находятся по этому адресу или идентификатору
Записи
«Key / Value pairs» – их значения указаны в первых 0x20 байтах атрибута. Они используются для связанных разделов метаданных с файлами, имена которых записываются в ключах, а содержимое – в значение.
Ниже приводится пример типичной Записи:
40 04 00 00 10 00 1A 00 08 00 30 00 10 04 00 00 @.........0.....
30 00 01 00 6D 00 6F 00 66 00 69 00 6C 00 65 00 0...m.o.f.i.l.e.
31 00 2E 00 74 00 78 00 74 00 00 00 00 00 00 00 1...t.x.t.......
A8 00 00 00 28 00 01 00 00 00 00 00 10 01 00 00 ¨...(...........
10 01 00 00 02 00 00 00 00 00 00 00 00 00 00 00 ................
00 00 00 00 00 00 00 00 A9 D3 A4 C3 27 DD D2 01 ........©Ó¤Ã'ÝÒ.
5F A0 58 F3 27 DD D2 01 5F A0 58 F3 27 DD D2 01 _ Xó'ÝÒ._ Xó'ÝÒ.
A9 D3 A4 C3 27 DD D2 01 20 00 00 00 00 00 00 00 ©Ó¤Ã'ÝÒ. .......
00 06 00 00 00 00 00 00 03 00 00 00 00 00 00 00 ................
5C 9A 07 AC 01 00 00 00 19 00 00 00 00 00 00 00 \..¬............
00 00 01 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
00 00 00 00 00 00 00 00 01 00 00 00 00 00 00 00 ................
00 00 00 00 00 00 00 00 20 00 00 00 A0 01 00 00 ........ ... ...
D4 00 00 00 00 02 00 00 74 02 00 00 01 00 00 00 Ô.......t.......
78 02 00 00 00 00 00 00 ...(cutoff) x.......
Здесь мы видим параметры записи, заданные в первой строке:
- общая длина – 4 байта = 0x440
- смещение ключа – 2 байта = 0x10
- длина ключа – 2 байта = 0x1A
- флаги / идентификатор – 2 байта = 0x08
- смещение значения – 2 байта = 0x30
- длина значения – 2 байта = 0x410
Запись заканчивается после значения, 0x410 байтов с начала и после значения 0x30 или 0x440 (что совпадает с общей длиной).
Запись соответствует файлу, созданному на диске.
Здесь первым атрибутом в значении записи является простой атрибут, который обсуждался выше, содержащий временные метки файла. Затем следует «File Reference Attribute List Header».
По меткам мы ищем записи со значениями «w/ flag» ‘0’ или ‘8’. Часто встречаются ‘4’ что указывает на Историческую Запись или Запись, которая с была изменена.
Поскольку записи имеют префикс их общей длины, их можно рассматривать как подкласс «Attribute».
«AttributeList» (заголовок списка) – содержит блок атрибутов.
На первый взгляд это простые атрибуты длиной 0x20, но при дальнейшем рассмотрении мы можем видеть, что он содержит длину большого блока атрибутов. После анализа «AttributeList», осталось прочитать оставшиеся заполнение байты в списке, прежде чем перейти к следующему атрибуту.
20 00 00 00 A0 01 00 00 D4 00 00 00 00 02 00 00 - заголовок списка с указанием общей длинны (0x1A0) и заполнения (0xD4)
74 02 00 00 01 00 00 00 78 02 00 00 00 00 00 00
80 01 00 00 10 00 0E 00 08 00 20 00 60 01 00 00
60 01 00 00 00 00 00 00 80 00 00 00 00 00 00 00
88 00 00 00 ... (разрез)
Directory Tree Branches (Ветви дерева каталогов)
Ветви дерева каталогов – это списки атрибутов, где каждый атрибут соответствует записи, значение которой ссылается на страницу, содержащую дополнительное содержимое каталога.
При обнаружении заголовка «AttributeList» со значением флага «0x301» мы должны
- перебрать атрибуты в списке,
- проанализировать их записи,
- использовать «dword» в каждом значении в качестве страницы для повтора процесса обхода каталога.
Дополнительные файлы и подкаталоги, найденные на указанных страницах, должны быть добавлены к списку содержимого текущего каталога.
SubDirectories
«SubDirectories» – это записи в списке атрибутов каталога, ключ которых содержит флаг метаданных каталога (0x20030), а также имя подкаталога.
Значением этой записи является соответствующий идентификатор объекта, который можно использовать для поиска страницы, содержащей подкаталог в таблице объектов.
Типичный подкаталог «Record»:
70 00 00 00 10 00 12 00 00 00 28 00 48 00 00 00
30 00 02 00 73 00 75 00 62 00 64 00 69 00 72 00 - здесь мы видим ключ содержащий флаг (30 00 02 00) за которым следует имя каталога ("subdir2")
32 00 00 00 00 00 00 00 03 07 00 00 00 00 00 00 - здесь мы видим идентификатор объекта и первое значение qword (0x730)
00 00 00 00 00 00 00 00 14 69 60 05 28 dd d2 01 - здесь мы видим временные метки каталога
cc 87 ce 52 28 dd d2 01 cc 87 ce 52 28 dd d2 01
cc 87 ce 52 28 dd d2 01 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 00 10 00 00 00 00
Подобные каталоги – это записи, ключ которых содержит флаг (0x10030), за которым следует имя файла.
Однако значение намного сложнее, мы обнаружили некоторые базовые атрибуты, позволяющие извлекать временные метки и содержимое из файловой системы, но еще предстоит сделать вывод о семантике значения этой записи.
Значение «File Record» состоит из нескольких атрибутов, хотя они появляются только один за другим, без заголовка списка. Мы по-прежнему можем анализировать их последовательно, учитывая, что все атрибуты имеют индивидуальный префикс с их длиной, а длина значения записи файла дает нам общий размер блока.
Первый атрибут содержит 4 метки времени файла со смещением, заданным пятым байтом атрибута (хотя эта позиция может быть случайной, поскольку метки времени могут просто находиться в фиксированном месте в этом атрибуте).
Второй атрибут, является заголовком списка атрибутов, содержащего «Ссылку на файл».
В этом атрибуте первый содержит длину файла, а второй – заголовок для еще одного списка. Еще этот атрибут содержит запись, значение которой содержит ссылку на страницу, где находится содержимое файла.
----------------------------------------
| ... |
----------------------------------------
| File Entry Record |
| Key: 0x10030 [FileName] |
| Value: |
| Attribute1: Timestamps |
| Attribute2: |
| File Reference List Header |
| File Reference List Body(Record) |
| Record Key: ? |
| Record Value: |
| File Length Attribute |
| File Content List Header |
| File Content Record(s) |
| Padding |
----------------------------------------
| ... |
----------------------------------------
Несмотря на сложность, каждый уровень может быть проанализирован таким же образом, как и все другие атрибуты и записи, просто нужно разобрать атрибуты и правильно определить их уровни и структуру.
Что касается фактических значений, длина файла всегда видна с фиксированным смещением в пределах его атрибута (0x3c) и указатель содержимого, находится во втором значении «qword» файла записи. Этот указатель представляет собой простую ссылку на страницу, содержимое файла которой можно прочитать дословно.

Хотя «ReFS» обладает повышенной безопасностью и эффективностью хранения данных, это не может полностью защитить важные данные от случайного удаления, повреждения вирусами или другими возможностями утери информации. Такие ситуации следует обязательно учитывать и обзавестись надежным инструментом для решения проблем с удаленными файлами.
Алгоритм поиска программы для восстановления данных Hetman Partition Recovery
Решением этой проблемы будет специальная утилита для быстрого восстановления данных.
Hetman Partition Recovery позволяет проанализировать дисковое пространство под управлением файловой системой «ReFS» с помощью алгоритма сигнатурного анализа. Анализируя устройство сектор за сектором, программа находит определенные последовательности байт и отображает их пользователю. Восстановление данных с дискового пространства «ReFS» не отличается от работы с файловой системой «NTFS».
При быстром анализе программа ищет заголовок тома «Volume Header», который находится в нулевом секторе, и его копия лежит в последнем секторе. В заголовке находиться нужная информация для дальнейшего анализа, а именно количество байт в секторе и количество секторов в кластере. Затем определив эти параметры находит «Superblock», который лежит в 30-ом блоке. Суперблок имеет 2 копии одна находиться в третьем блоке с конца, и вторая во втором блоке. Из суперблока программа определяет ссылки на чекпоинты, есть 2 чекпоинта, они находятся по указанным адресам, которые лежат в суперблоке. Перейдя по этим двум адресам, программа находит «Virtual Allocated Clock», по этому параметру определяется какой из чекпоинтов актуальный в данный момент. Как известно Windows изменяет сначала 1 чекпоинт и только при успешной записи дублирует информацию во второй.
В чекпоинте (Checkpoint) находится основные таблицы. Из него вычитывается заголовок страницы «Page Header» и затем блок с данными. По блоку с данными мы получаем поинтеры (Pointers) каждой из таблицы (ссылки на все основные таблицы).
Чтобы переводить виртуальные адреса в физические нужно найти «Container Table». И затем по виртуальному адресу идет поиск «Object ID Table» для того чтобы получить все таблицы.
Далее поиск информации идет постранично, определяя их уровень. Если это нулевой уровень – лист, то считываются нужные нам данные. Если нет, то программа ищет путь к следующему уровню пока не доберется до нулевого где лежат наши данные.
Даже если один из этих элементов структуры файловой системы поврежден алгоритм нашей программы при полном анализе позволяет исключить эти звенья и добраться до нужной информации, которую нужно восстановить.
Будущее новой файловой системы довольно туманно. Microsoft может доработать «ReFS» для замены, устаревшей «NTFS» во всех версиях Windows. На данный момент «ReFS» не может использоваться повсеместно и служит только для определенных задач.


Комментарии: